This spring, I will the “Using Twitter Data in Social Science” course another spin. The course introduces students to the work with digital trace data in the social sciences. The course builds on a tutorial on the work with Twitter data that Pascal Jürgens and I published last year.
Over the course, students will learn fundamental techniques of data collection preparation, and analysis with digital trace data in the social sciences. In this, we will focus on working with the microblogging-service Twitter. Over the course, students are expected to become proficient in the use of two programming languages, Python and R.
The course is designed for students without prior training in programming or exmploratory data analysis. Still, by the end of course students are expected to independently perform theory-driven data collections on the microblogging-service Twitter and use these data in the context of a series of specified prototypical analyses. So make sure to take the time over the course of the semester to get acquainted with Python, R, and potentially SQL.
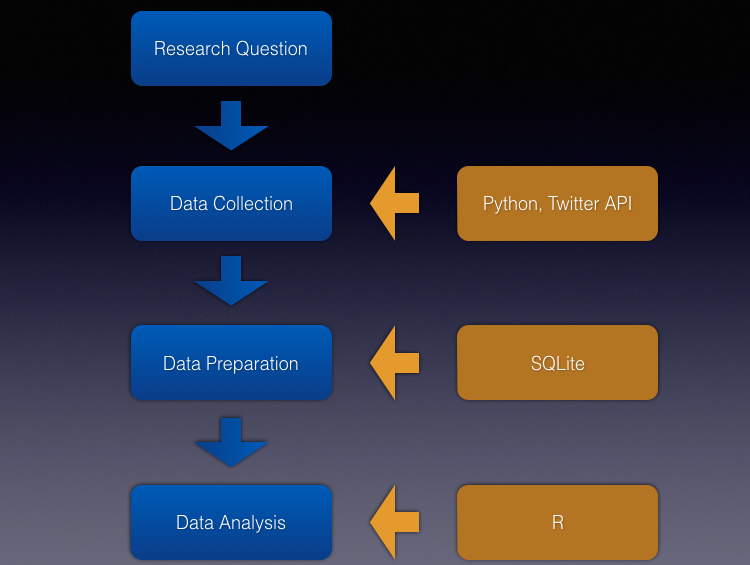
We will start the course by focusing on conceptual issues associated with the work with digital trace data. Students will then learn to use fundamental practices in the use of the programming language Python. Following this, we will collect data from Twitter’s APIs through a set of example scripts written in Python. After downloading data from Twitter through Python, we will load these data into a SQLite database for ease of access and flexibility in data processing tasks. Finally, we will discuss a series of typical analytical procedures with Twitter-data. Here, we will focus on counting entities and establishing their relative prominence, time series analysis, and basic approaches to network analysis. For these analyses, we will predominantly rely on R.
The course itself follows closely the outline provide by Pascal’s and mine paper A Tutorial for Using Twitter Data in the Social Sciences: Data Collection, Preparation, and Analysis. Students will be introduced to the work with Twitter-data through a set of example scripts developed in the context of the tutorial and available on GitHub.
Here is the course’s syllabus.
You can find detailed information on the content of the sessions, background readings, slides, and example code at the dedicated posts per session:
Session 1: Introduction and Conceptual Issues in the Use of Digital Trace Data in Social Science, Computational Social Science, Digital Methods, and Big Data [Slides]
Session 2: Set Up and Introduction to Collecting Data on Twitter [Slides/Code]
Session 3: Introduction to Python [Code]
Session 4: Collecting Data Through Twitter’s API [Code]
Session 5: How to Find A Research Question?
Session 6: Loading Twitter Data Into a Database [Code]
Session 7: Extracting Data for Typical Analyses: Counts and Time Series [Code]
Session 8: Sample Analyses: Networks [Code]
Session 9: Presentation and Discussion of Students’ Research Projects Pt. 1
Session 10: Presentation and Discussion of Students’ Research Projects Pt. 2
Session 11: Where to take it from here? Discussion of Open Questions and Paper
In addition to the tutorial a series of texts are encouraged background readings:
Using Digital Trace Data in the Social Sciences:
- David Donoho. 50 Years of Data Science. Paper presented at the Tukey Centennial workshop, Princeton, NJ. Sept. 18 (2015).
- Bradley Efron, and Trevor Hastie. Computer Age Statistical Inference: Algorithms, Evidence and Data Science. Cambridge: Cambridge University Press.
- James Howison, Andrea Wiggins, and Kevin Crowston. “Validity issues in the use of social network analysis with digital trace data“. In: Journal of the Association for Information Systems 12.12 (2011), pp. 767–797.
- Andreas Jungherr. Analyzing Political Communication with Digital Trace Data: The Role of Twitter Messages in Social Science Research. Cham, CH: Springer, 2015.
- Andreas Jungherr, Harald Schoen, and Pascal Jürgens. “The mediation of politics through Twitter: An analysis of messages posted during the campaign for the German federal election 2013“. In: Journal of Computer-Mediated Communication (2015). doi: 10.1111/jcc4.12143.
- Andreas Jungherr, Harald Schoen, Oliver Posegga, and Pascal Jürgens. “Digital Trace Data in the Study of Public Opinion: An Indicator of Attention Toward Politics Rather Than Political Support“. In: Social Science Computer Review. (2016). doi: 10.1177/0894439316631043
- Matthew Salganik. Bit by Bit: Social Research in the Digital Age. (Forthcoming).
Python:
- Nick Eubank (2015) Data Analysis in Python.
- Mark Lutz (2013) Learning Python, 5th Edition. O’Reilly Media, Inc.
- Wes McKinney (2012) Python for Data Analysis. O’Reilly Media, Inc.
R:
- Winston Chang (2012) R Graphics Cookbook. O’Reilly Media, Inc.
- Richard Cotton (2013) Learning R. O’Reilly Media, Inc.
- Robert Kabacoff (2015) R in Action. 2nd ed. Manning Publications.
Data Collection Online:
- Matthew A. Russell (2013) Mining the Social Web: Data Mining Facebook, Twitter, LinkedIn, Google+, GitHub, and More, 2nd Edition. O’Reilly Media, Inc.